첫 글이네요 >< 부족한 점이 많으니, 틈틈히 피드백 해주시면 감사하겠습니다.
VAE의 목적
" We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case"
Stochastic Variational Inference
Variational Inference는 사후확률(posterior) 분포 \(p(z \vert x)\)를 다루기 쉬운 확률 분포 q(z)로 근사하는 것을 말한다. 이는 사후확률 분포 계산이 어렵기(intractable) 때문이다.
여기서 KLD(Kullback-Leibler divergence) 개념이 등장한다. 간단하게 두 확률 분포 차이 \(p(z \vert x)\) & \(q(z)\)를 계산하는데 사용하는 함수이다. KLD가 줄어드는 쪽으로 q(z)를 업데이트하는 과정을 통해 사후 확률을 잘 근사하는 q*(z)를 얻는게 VI의 아이디어이다.
학습된 근사 사후 추론 모델은 recognition, denoising, representation, visualization의 목적으로 활용될 수 있다. 본 알고리즘이 인식(recognition) 모델에 사용될 때, 이를 Variational Auto-Encoder라고 부를 것이다.
그렇다면 업데이트 하는 방법이 핵심이 되겠네요?! => SVI: Gradient Descent를 VI에 적용한 방법
참고
문제 시나리오
i.i.d x로 이루어진, \(X = \sum\limits_{i=1}^N{x_i}\)를 가정한다. 또한 해당 x는 관측되지 않은 연속 확률 변수 z를 포함한 어떠한 random process에 의해 만들어졌다고 가정한다.
intractability

해결방안 : \(p(z \vert x)\)와 근접할 수 있는 \(q(z \vert x)\)라는 additional network를 정의하자.
a large data
데이터가 너무 크면 배치 최적화는 연산량이 매우 많다. 우리는 작은 미니배치나 데이터포인트에 대해 파라미터 업데이트를 진행하고 싶은데, Monte Carlo EM과 같은 Sampling Based Solution은 데이터 포인트별로 Sampling Loop를 돌기 때문에 너무 느리다.
해결방안
- 효율적인 ML/MAP 근사 추정 제안
- 파라미터 θ의 선택에 따라 관측값 x가 주어졌을 때 잠재 변수 z에 대한 효율적인 근사 사후 추론을 제안
- 변수 x에 대한 효율적인 근사 Marginal Inference를 제안한다.
Kullback-Leibler Divergence
위에서 언급한 KLD에 대해서 한번 더 다루고 가야, 하단에서 다룰 Margianal Likelihood에 대해 알 수 있다.
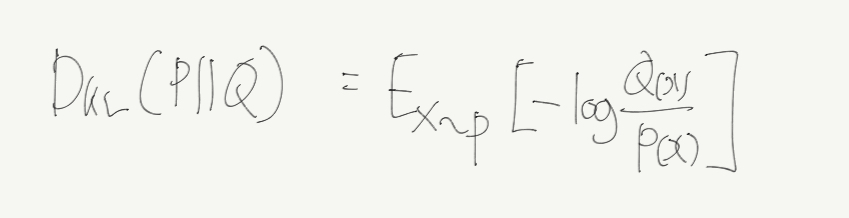
다음은 KLD식이다. P와 Q분포가 동일하면 DKL은 0을, 다르면 다를수록 높은 값을 갖게 된다.
참고
Marginal Likelihood

다음은 데이터 포인트 하나에 대한 Marginal Likelihood를 재표현한 식이다.
다음 정리를 통해, \(p(z \vert x)\)가 Intractable하므로, 계산할 수 없는 KL부분(우측)을 제외한 Tractable Lower bound를 구할 수 있다.
이때 해당 intractable KL term은 항상 >=0 이다.
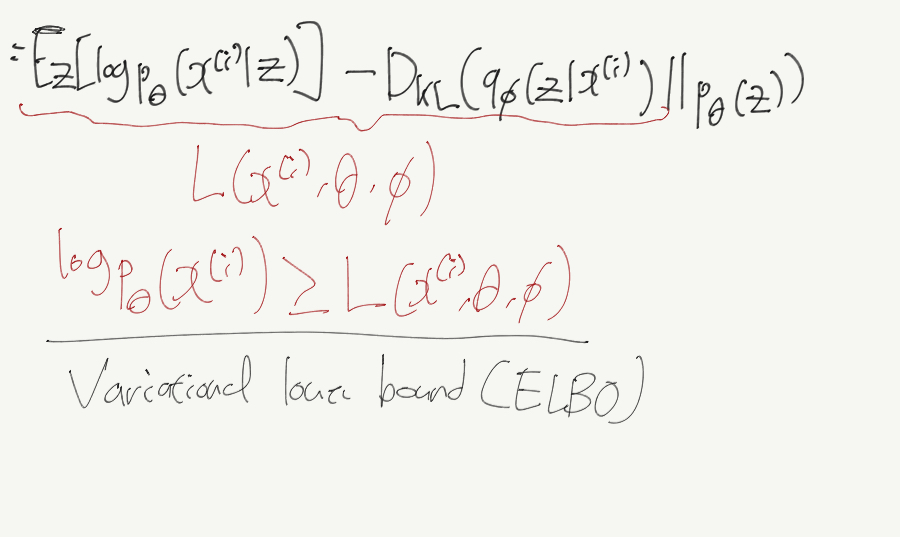
다음은 위의 수식을 거쳐 구한 Marginal Likelihood의 Variational Lower Bound(ELBO)이다.
이 때 학습은 당연하게도 Lower bound를 최적화하는 방향으로 이루어지게 된다.
How?
위에서 언급했지만, Lower Bound L(θ,ϕ;x(i))를 θ,ϕ에 대해서 미분하고 최적화하고 싶은데 쉽지 않다.
이러한 타입의 문제에 대해 일반적으로 쓰이는 Monte Carlo Gradient Estimator는 굉장히 큰 분산을 갖고 있어서 우리의 목적에 적합하지 않다.
참고: Variational bayesian inference with stocahstic search, David M Blei, ICML-12
SGVB estimator
mild condition 아래에서, 근사 Posterior \(q(z \vert x)\)를 Reparameterize할 수 있다. 이 때 mild condition에 대해 서는 뒤에서 다루겠다. (Reparametrization trick)
\(q(z \vert x)\)라는 근사 Posterior로부터 Samples를 생성하기 위해, 논문에서는 다른 방법을 사용하였다. z가 연속형 확률 변수이고, z ~ \(q(z \vert x)\)가 어떠한 조건부 확률을 따른다고 하자. 이 때 z를, z = g(ϵ,x)라는 Deterministic 변수라고 표현할 수 있다.
이 떄 ϵ는 독립적인 Marignal p(ϵ)를 가지는 auxiliary variable이고, g(.)는 ϕ에 의해 parameterized되는 vector-valued 함수이다.
이 reparameterization을 통해 근사 posterior의 기댓값을 ϕ에 대해 미분 가능한 기댓값의 Monte Carlo 추정량으로 재표현하는 데에 사용될 수 있다.
우선 ELBO에서 좌측은 우선 킵해놓고 우측 \(DKL(q(z \vert x) || p(z))\)를 조금 보겠다. 해당 식은 적분 수식을 직접 풀어 계산할 수 있다. (appendix 참고)
이제 남은 것은 expected reconstruction error에 해당하는 \(Ez(logp(x \vert z))\)를 풀어주는 것이다.

다음의 보라색 부분은 L개의 Sample을 뽑아 이에 대한 근사치로 추정량을 구하는 것을 보여준다.
Prior로부터 나온 근사 Posterior에 대한 KLD 값인 핑크색 항은 Regularizer의 역할 (qϕ 라는 inference 를 위한 확률분포가 pθ 와 비슷하게끔 만드는)을 한다.
Stochastic Gradients 계산

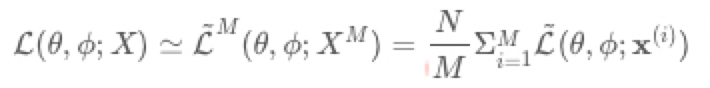
Reparameterization Trick
나는 왜있을까..
안민용
Engineer, industry executive, research enthusiast. Avid learner with diverse interests in coding, machine learning, artificial intelligence and reinforcement learning. 17+ years of experience working in multinational corporations.

Comments