StackGAN의 목적
text-to-image의 시초라고도 볼 수 있지 않을까 싶다. 이 논문은 단순히 Vanila GAN에 upsampling layers를 더한 GAN_INT-CLS 보다는 GAN을 두 층을 쌓아서(Stack) 더 좋은 성능을 낼 수 있음을 보여준다.
조금 더 디테일하게 들어가보자면 두개의 sub-problems로 나눈다.
- 원초적인 형태, 색, 그리고 텍스트에 알맞는 object를 스케치 한다.
- 텍스트 설명을 한번 더 입력으로 받고, 위에서 나온 1차적인 스케치에 고화질로 덧칠한다.
문제 시나리오
기존의 바닐라 GAN을 이용해서 text-to-image를 구현하는 것은 굉장히 어렵다. 보통 GAN에다가 upsampling layers를 더해서 고화질 이미지를 만드는 경우, 1. 높은 학습 instability와 2. nonsensical outputs를 만들어 낸다.
그렇다고 저화질 이미지를 만드는 경우 => 디테일한 부분 혹은 생생한 부분(e.g. 새의 눈동자)들이 부족하다.
해결
- 이에 저자는 사람 페인터가 그림을 그리는 방법에서 착안을 받아, 목적에서 언급한 두개의 방법을 두개의 Stacked Generative Adversarial Networks로 구현
- 제한된 학습 text-image pairs는 text conditioning manifold의 부족으로 이어진다. 이에 Conditioning Augmentation technique을 제시하여, latent conditioning manifold에서 약간의 random 작은 변화를 일으키고, 만들어지는 이미지들의 다양성을 증가시킨다.
traing procedure
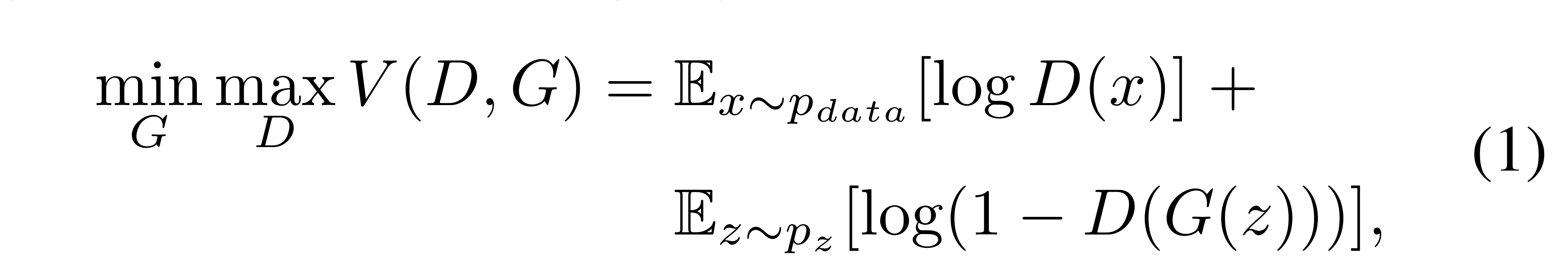
여기서 x는 true data distribution에서의 real image, z는 noise vector
Model Architecture
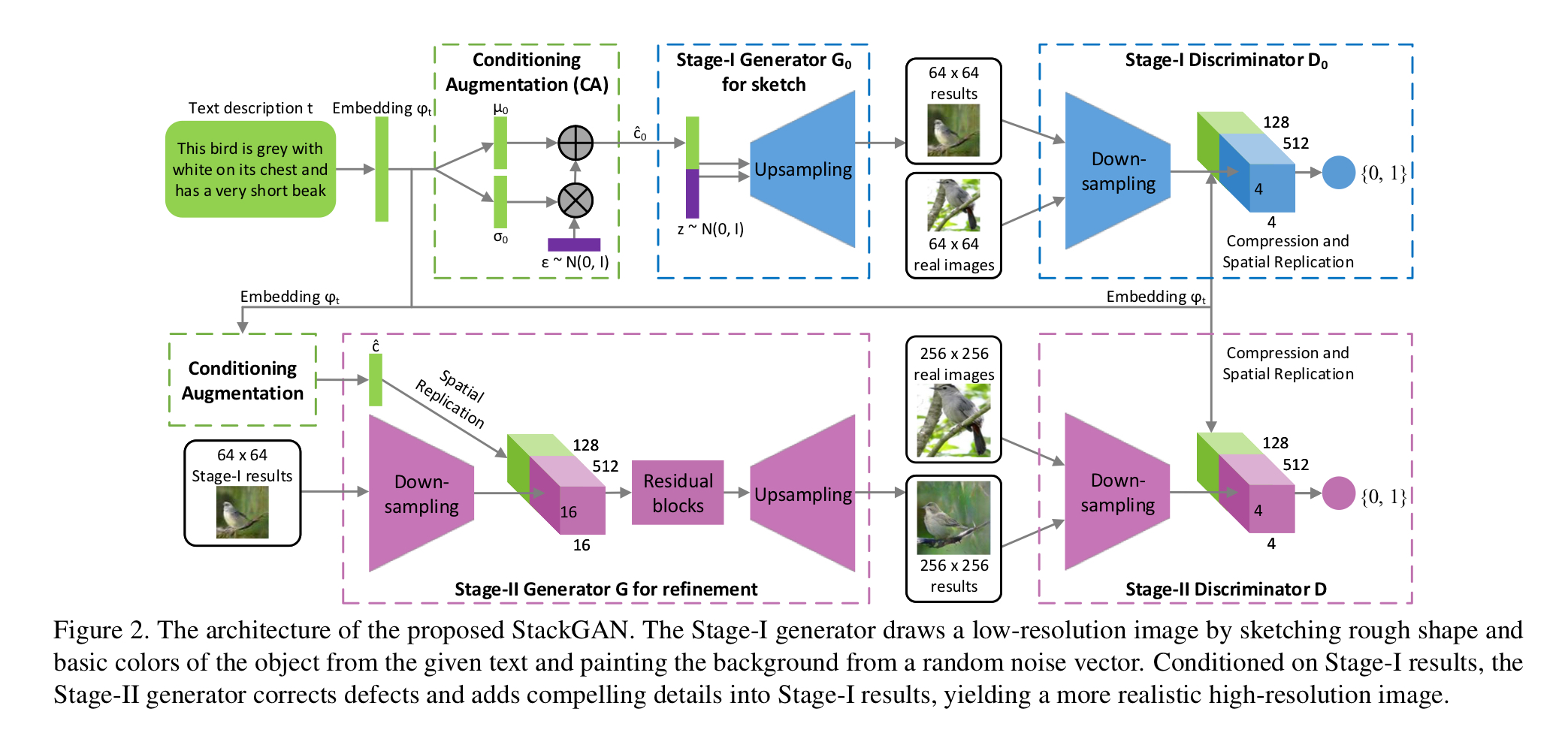
Conditioning Augmentation
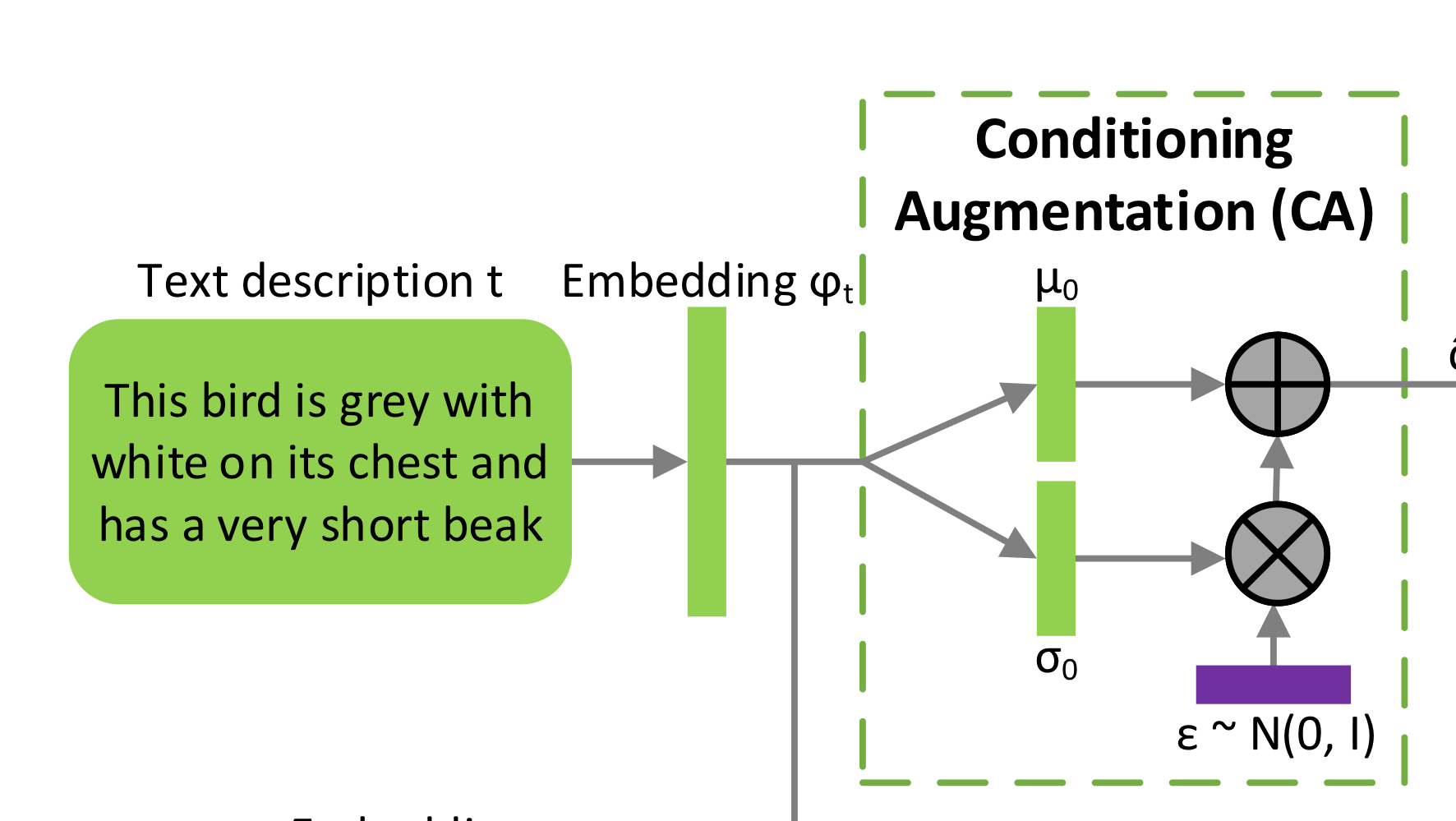
텍스트 t는 encoder를 통해 인코딩 되고, 텍스트 임베딩 ⍴가 된다. (이 때 encoder는 FC Layer이다.) 이 후 한번 더 nonlinearly 변형되어서 generator의 input으로 사용될 수 있는 conditioning latent variables가 된다.
** 여기서 문제인 점이, data의 수가 제한되어 있기에, lantent data manifold에서의 불연속성을 야기하기도 한다.
이를 해결하기 위해 Conditioning Augmentation technique를 제시한다.
latent variable c를 텍스트 임베딩 ⍴를 이용해 만들어진 independent Gaussian distribution으로 부터 랜덤으로 뽑아낸다.
(VAE의 reparametrization trick과 비슷한거 같네요, 그런데 실제로 이 기법을 이용했네요!)
Stage- 1&2 GAN
위에 Model Architecture에서 어떻게 모델이 구성되고 돌아가는지를 확인할 수 있다.
여기서 몇가지 특이한 점 (바닐라 GAN과의 차이점)이 있다. 첫 번째는 Discriminator 학습에 있어서, real images와 corresponding text descriptions을 positive pair로 제공받는다.
안민용
Engineer, industry executive, research enthusiast. Avid learner with diverse interests in coding, machine learning, artificial intelligence and reinforcement learning. 17+ years of experience working in multinational corporations.

Comments